
We’re excited to announce that multi-node and high availability (HA) support in Embedded Cluster is now generally available as of version 2.4.0. This release represents a major milestone in simplifying how software vendors package and deliver their Kubernetes applications to customer-managed environments.
See the 2.4.0 Release Notes here.
What’s New in 2.4.0?
With this release, it’s never been easier for vendors to deliver a highly available Kubernetes application, without requiring customers to know anything about Kubernetes.
Here’s what’s new:
Multi-node Embedded Clusters: GA
The Admin Console now guides end-users through the process of adding new nodes so there’s no guesswork or mistakes.
When a user installs the first node and reaches the “Configure the Cluster” step, the Admin Console shows three commands users can copy and paste to join nodes. All necessary assets are served from the initial node, so users no longer have to download large air gap bundles to every node. For large clusters, this can significantly reduce the time and bandwidth it takes to set up a cluster.

💡 High Availability (HA) Made Simple
Once three controller nodes are added, users are prompted to enable HA so data and services are replicated across nodes to withstand node failures.
No kubectl commands. No YAML editing. Just a smooth UI flow and a highly available cluster. Below is a diagram detailing the architecture of Embedded Cluster’s highly available setup.

Programmatic Joins for Automation
Need to automate multi-node installs? We’ve got you covered. A new join print-command command outputs the exact command users (or scripts) can run to add additional nodes. While node roles aren’t yet supported in this automation flow, controller joins work seamlessly—and without any UI interaction.
Node Roles: Still in Beta, But Improvements Coming
Node roles let vendors define different types of nodes for their clusters—such as nodes dedicated to databases or GPU workloads. These roles map to Kubernetes labels, enabling intelligent workload scheduling without requiring customers to understand Kubernetes internals.
From the admin console, users can simply select the type of node they want to add (e.g., primary, gpu-worker, etc.), and the system takes care of the rest.
We’re actively seeking feedback on node roles—so if your application could benefit from flexible workload placement, let us know.
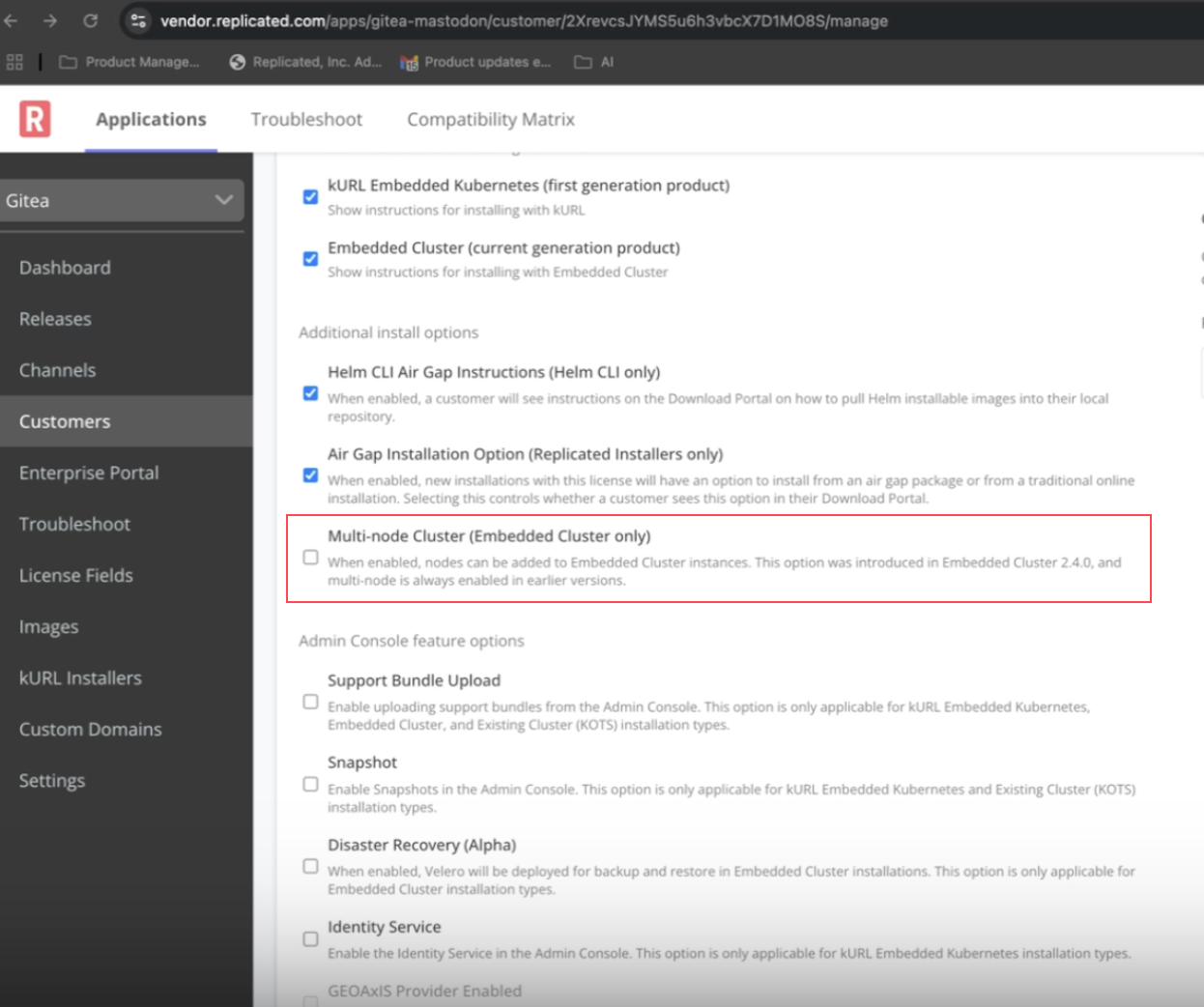
Configurable Deployment Experiences
When creating customers in the Vendor Portal, vendors now have control over whether a customer’s installation experience includes multi-node support:
- Want to keep things simple? Disable multi-node support for a streamlined single-node install experience.
- Offer larger clusters? Easily enable multi-node support for a customer.
When multi-node is disabled, the cluster configuration step disappears from the UI and only a single node is installed—removing any confusion or unnecessary complexity.
Final Thoughts
This update continues our mission to make Kubernetes simple for application vendors and their end users. With Embedded Cluster multi-node and high availability now GA, you can confidently deliver scalable, production-grade environments that install with just a few clicks.
If you’re already offering multi-node support, make sure to test your deployments using these new tools—and take advantage of the automation options to streamline your CI workflows.